
Brak odpowiedniej organizacji często prowadzi do marnowania czasu i stresu, a problem ten dotyka wielu z nas. To idealne zadanie dla AI, które z pewnością wkrótce stanie się standardem w tego typu podobnych problemach.
Taka funkcjonalność może okazać się niezwykle pomocna w różnych branżach, np. dla mechaników samochodowych, lekarzy, fizjoterapeutów, makijażystek i wielu innych, gdzie zarządzanie grafikiem jest kluczowe. A grafik to rzecz święta! Ustalanie, odwoływanie, przesuwanie terminów… to wyzwanie, które potrafi spędzać sen z powiek.
Taka funkcjonalność może okazać się niezwykle pomocna w różnych branżach, np. dla mechaników samochodowych, lekarzy, fizjoterapeutów, makijażystek i wielu innych, gdzie zarządzanie grafikiem jest kluczowe. A grafik to rzecz święta! Ustalanie, odwoływanie, przesuwanie terminów… to wyzwanie, które potrafi spędzać sen z powiek.
Wykorzystując czas przeznaczony na rozwój, który zapewnia mi firma Connect Point, postanowiłem stworzyć prototyp sekretarki AI, która pomoże w zarządzaniu kalendarzem.
Do tego celu wykorzystałem framework LlamaIndex, który pozwala na tworzenie aplikacji AI integrujących modele językowe z prywatnymi danymi. Aplikacje tego typu nazywana jest: RAG (Retrieval-Augmented Generation) – czyli generowanie wspomagane wyszukiwaniem. Technika ta polega na połączeniu zdolności modelu językowego z zewnętrznymi źródłami danych, aby zapewnić bardziej precyzyjne i kontekstowe odpowiedzi. Dzięki temu AI może nie tylko generować tekst, ale również korzystać z danych dostarczonych przez użytkownika.
Założenia:
Chcąc stworzyć moją wersję sekretarki AI, postawiłem sobie kilka założeń:
-
Wgląd w Google Calendar
Sekretarka powinna mieć dostęp do mojego kalendarza Google, aby móc zarządzać spotkaniami. Dzięki API Google Calendar mogłem zintegrować aplikację z kalendarzem, umożliwiając AI odczytywanie dostępnych terminów i tworzenie nowych wydarzeń. -
Komunikacja za pomocą chatu
Sekretarka będzie komunikować się z otoczeniem za pomocą chatu, co pozwala na naturalną interakcję z użytkownikiem. Skorzystałem z LlamaIndex, aby zintegrować model językowy z interfejsem chatowym, co zapewnia intuicyjną komunikację bez potrzeby korzystania z dodatkowych aplikacji. -
Umawianie spotkań w sugerowanych terminach
Sekretarka powinna umawiać spotkania w terminie zasugerowanym przez klienta. Aplikacja analizuje propozycje terminów i dopasowuje je do dostępnych okienek w kalendarzu. -
Tworzenie wydarzeń w kalendarzu
Jeśli termin jest dostępny, sekretarka tworzy nowe wydarzenie w kalendarzu. Jeśli termin jest zajęty, AI proponuje inne dostępne okienka czasowe.
Jak to działa
Każdy dostępny model LLM (Large Language Model) posiada ogólną wiedzę, która powstała w wyniku trenowania sieci neuronowej na dużych zbiorach danych. Najmniejsze modele, takie jak np. KingNish/Qwen2.5-0.5b-Test-ft, to pliki o wielkości około 1 GB. Z kolei największe ogólnie dostępne modele LLM (więcej tutaj) mogą zajmować setki gigabajtów i wymagają niezwykle wydajnych, a co za tym idzie, kosztownych komputerów do ich uruchomienia.
Najprostszym sposobem przekazania modelowi dodatkowych informacji jest użycie tzw. promptu. W tym artykule pomijamy bardziej zaawansowane techniki, takie jak fine-tuning (to temat na osobny wpis), i skupiamy się na metodzie RAG (Retrieval-Augmented Generation), która opiera się na promptach.
Prompt to nic innego jak tekst, którym rozpoczynamy interakcję z modelem. Aby model mógł zrozumieć prompt, przetwarza go na swój „język” poprzez konwersję tekstu na tzw. embeddings – numeryczne reprezentacje danych ułożone w logiczny sposób.
Oto przykład:
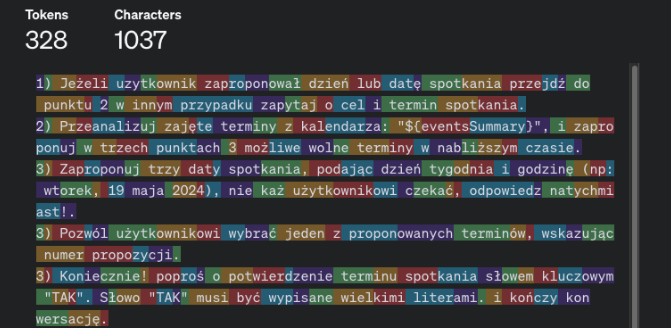
Zastosujemy dynamiczny prompt:
( funkcja JS która uzupełni treść o dane z kalendarz google za pomocą google calendar api za pomocą funkcji getFormattedDate() ):

Tokenizacja:
Biblioteka llamaindex dzieli dane na tokeny. Tą wartość można konfigurować per model
Nasza aplikacja korzysta z modelu OpenAI GPT 3.5 i dla takiego modelu zalecana jest wartość tak jak poniżej:

Pod tym linkiem można przetestować jak OpenAi tokenizuje zapytanie.
Należy pamiętać, że poniższy opis jest mocno uproszczony. Ale chodzi tutaj o podstawowe zrozumienie działania takich aplikacji.
Najpierw prompt dzielony jest na porcje chunki:
[„Two”, „##ja”, „rola”, „to”, „asystent”, … „.”]
(Znak „#” wskazuje na pod-słowo kontynuujące poprzedni token.)
Następnie odbywa się mapowanie tokenów na indeksy:
Każdy token jest zamieniany na unikalny identyfikator liczbowy zgodnie ze słownikiem modelu, który w praktyce wygląda tak:
![]()
Tworzenie embeddingów:
Każdy indeks jest mapowany na wektor liczb rzeczywistych (embedding). Na przykład:

Zapisane lokalnie dane w postaci embeddings w trakcie wykonywania zapytania są kojarzone z treścią pytania.
Skojarzone fragmenty są doklejane do pytania i przesyłane do modelu. Ten mechanizm pozwala finalnie na przekazanie szerszego kontekstu.
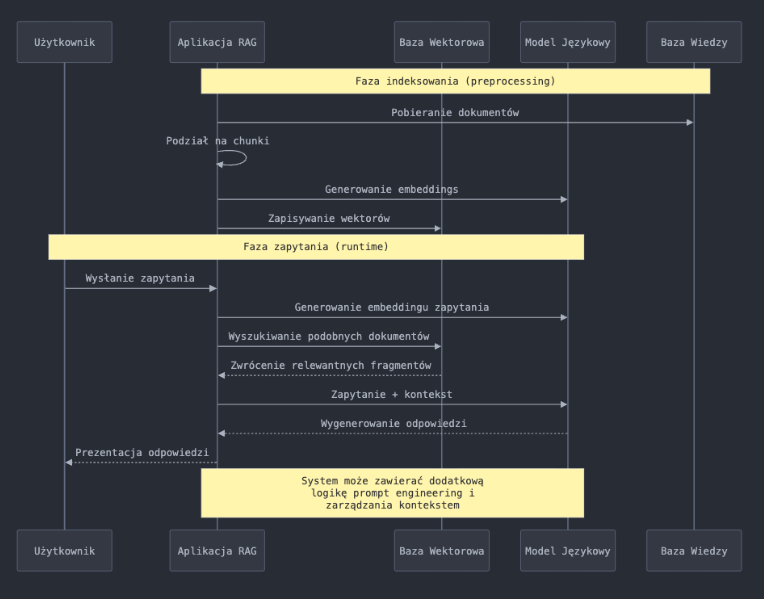
Aby podsumować i lepiej zobrazować ten proces posłużymy się diagramem:
Warto wiedzieć:
Każdy model językowy ma limit tokenów, które mogą być użyte w oknie konwersacji.
Ilość pytań w konwersacji powoduje sumarycznie zwiększenie liczy użytych tokenów co finalnie przekłada się na zwiększenie kosztów użytkowania, ale też na spadek jakości odpowiedzi. Dlatego bardzo ważna jest optymalizacja promptów.

Przekroczenie limitu: Gdy suma tokenów w rozmowie zbliża się do limitu, model najczęściej zaczyna usuwać najstarsze wiadomości z kontekstu, aby zrobić miejsce dla nowych. Dlatego często zdarza się że im dłuższa jest konwersacja tym mniej dokładne i spójne są informacje zwracane przez model językowy.
Przetwarzanie informacji na przykładzie aplikacji:
Tak więc embeddings są wejściem do sieci neuronowej, która przetwarza je w celu zrozumienia znaczenia zdania i wykonania odpowiedniego zadania.
Do rzeczy … :
Tworzenie indeksu
Użyjemy LlamaIndex Dokument do stworzenia indeksu (VectorStoreIndex), który przechowuje informacje w sposób umożliwiający szybkie wyszukiwanie.

Retriever
Retriever jest tworzony z indeksu i jest odpowiedzialny za wyszukiwanie najbardziej podobnych informacji na podstawie zapytania użytkownika.

Silnik czatu
ContextChatEngine używa retriever do przetwarzania zapytań użytkownika. Silnik czatu analizuje zapytanie, wyszukuje odpowiednie informacje w indeksie i generuje odpowiedź. Dzięki indeksowi model językowy zna nasz kalendarz i wie, co ma z tymi danymi robić.

Interakcja z użytkownikiem
Użytkownik wprowadza zapytania, a silnik czatu przetwarza je, używając kontekstu przechowywanego w indeksie, aby wygenerować odpowiednie odpowiedzi.
Konwersacja przebiega w pentli while .. do chwili, kiedy użytkownik potwierdzi termin wpisując z klawiatury wpisując ‘TAK”

Interakcja z użytkownikiem
Potwierdzenie terminu “TAK” powoduje wyjście z pętli i utworzenie nowego kontekstu, czyli nowej rozmowy.
Finalnie powstała mała aplikacja w TypeScript i NodeJS, która po uruchomieniu pozwala użytkownikowi na komunikację z modelem LLM, który zna nasz kalendarz. Działanie aplikacji możesz zobaczyć tutaj:
Kod aplikacji znajdziesz tutaj:
https://github.com/Himmelbub/sekretarkaAi
Podsumowanie
Jak widać na powyższym przykładzie, wykorzystywanie modeli LLM w tworzeniu oprogramowania nie jest rzeczą skomplikowaną. Wykorzystując nowoczesne i szybko rozwijane frameworki, takie jak Llamaindex czy LangChain, jesteśmy w stanie w szybki sposób dodać integrację z AI. Do finalnego efektu ważne jest natomiast dogłębne przeanalizowanie tematów bezpieczeństwa oraz optymalizacji wyników zwracanych przez model.